
 020-66889888
020-66889888
之前的几篇文章中分别和大家介绍了自己在学习过程中的网络的搭建和批处理
HUST小菜鸡:Pytorch搭建简单神经网络(一)——回归HUST小菜鸡:Pytorch搭建简单神经网络(二)——分类HUST小菜鸡:Pytorch搭建简单神经网络(三)——快速搭建、保存与提取HUST小菜鸡:Pytorch搭建简易神经网络(四)——批处理在网络的训练阶段,都主要到了定义了一个优化器
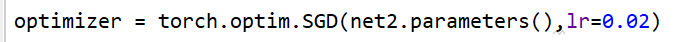
我们都采用的随机梯度下降的优化方式,来实现整个网络的优化与回归,但是在实际中,有很多的优化方式,在Pytorch中文文档中关于优化器就给了我们详细的解释[1]
torch.optim是一个实现了各种优化算法的库。大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法
为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。为了构建一个Optimizer,你需要给它一个包含了需要优化的参数(必须都是Variable对象)的iterable。然后,你可以设置optimizer的参 数选项,比如学习率,权重衰减,等等。Optimizer也支持为每个参数单独设置选项。若想这么做,不要直接传入Variable的iterable,而是传入dict的iterable。每一个dict都分别定 义了一组参数,并且包含一个param键,这个键对应参数的列表。其他的键应该optimizer所接受的其他参数的关键字相匹配,并且会被用于对这组参数的 优化。
所有的optimizer都实现了step()方法,这个方法会更新所有的参数。它能按两种方式来使用:
optimizer.step()
这是大多数optimizer所支持的简化版本。一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数。optimizer.step(closure)
一些优化算法例如Conjugate Gradient和LBFGS需要重复多次计算函数,因此你需要传入一个闭包去允许它们重新计算你的模型。这个闭包应当清空梯度, 计算损失,然后返回。
对于不同的优化器有着什么样的优化效果,和方式,B站莫烦大佬用抽象的比喻对各种优化器的实现方式进行了阐述,感觉说的很好,这里直接上链接,有需要的小伙伴可以去看视频消化一下。
PyTorch 动态神经网络 (莫烦 Python 教学)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili本文结合自己的学习过程对各种优化器的学习性能进行展示
主要使用SGD,Momentum,RMSprop,Adam四种优化算法
import torch
import torch.utils.data as Data
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.autograd import Variable
#神经网络需要输入的数据形式为Variable的变量,但是经过自己的实验最新的pytorch,
#对于输入的tensor就可以进行处理,可以不需要转化成Variable的环节
LR = 0.01
BATCH_SIZE = 20
EPOCH = 20x=torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y=x.pow(2)+0.1*torch.normal(torch.zeros(x.size()))
# plot dataset
plt.scatter(x,y)
plt.show()为了更值观的看出数据的结果这里调用plot将数据画了出来

torch_dataset=Data.TensorDataset(x,y)
loader=Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True)参照我之前的文章
HUST小菜鸡:Pytorch搭建简单神经网络(一)——回归class Net(nn.Module):
def __init__(self,n_input,n_hidden,n_output):
super(Net,self).__init__()
self.hidden1=nn.Linear(n_input,n_hidden)
self.hidden2=nn.Linear(n_hidden,n_hidden)
self.predict=nn.Linear(n_hidden,n_output)
def forward(self,input):
out=self.hidden1(input)
out=F.relu(out)
out=self.hidden2(out)
out=F.relu(out)
out=self.predict(out)
return out定义四个完全的神经网络用于比较不同优化算法的学习性能
net_SGD=Net(1,20,1)
net_Momentum=Net(1,20,1)
net_RMSprop=Net(1,20,1)
net_Adam=Net(1,20,1)为了使得后面可以进行循环处理,将网络放入一个list中
nets=[net_SGD,net_Momentum,net_RMSprop,net_Adam]对于四个相同的网络,分别采用不同的优化算法,将优化器也放进一个list中
optimizer_SGD=torch.optim.SGD(net_SGD.parameters(),lr=LR)
optimizer_Momentum=torch.optim.SGD(net_Momentum.parameters(),lr=LR, momentum=0.8)
optimizer_RMSprop=torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR, alpha=0.9)
optimizer_Adam=torch.optim.Adam(net_Adam.parameters(),lr=LR, betas=(0.9,0.99))
optimzers=[optimizer_SGD,optimizer_Momentum,optimizer_RMSprop,optimizer_Adam]敲黑板:细心的小伙伴这里肯定注意到了SGD优化算法和Momentum优化算法都采用的是SGD这个函数,唯一不同的就是多了一个Momentum这个参数,因为Momentum算法在随机梯度下降算法上多了一个方向动量,使其可以更快的收敛
损失函数采用同样的损失函数——均方损失函数
为了后面更好的画出结果,定义一个loss_his的list来存储每次训练的loss
loss_func=torch.nn.MSELoss()
losses_his=[[],[],[],[]]for epoch in range(EPOCH):
print(epoch)
for step ,(batch_x,batch_y) in enumerate(loader):
# b_x=Variable(batch_x)
# b_y=Variable(batch_y)
b_x=batch_x
b_y=batch_y
for net,optimizer,loss_his in zip(nets,optimzers,losses_his):
net_output=net(b_x)
loss=loss_func(net_output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_his.append(loss.item())对于代码中的一些难点这里详细解读一下
- 首先print(epoch)是为了通过终端可以看出这个网络在训练
- 我也尝试了对于传入神经网络的参数不转化为Variable的变量的形式发现也是可以运行的
- 采用循环的方式可以减少代码的复杂性,不用去写四个的训练代码,直接进行训练就可以
- for net,optimizer,loss_his in zip(nets,optimzers,losses_his) 采用zip的方式将其捆绑在一起,使得代码的结构更美观。
labels=['SGD','Momentum','RMSprop','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i],lw=0.5)
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim(0,0.3)
plt.show()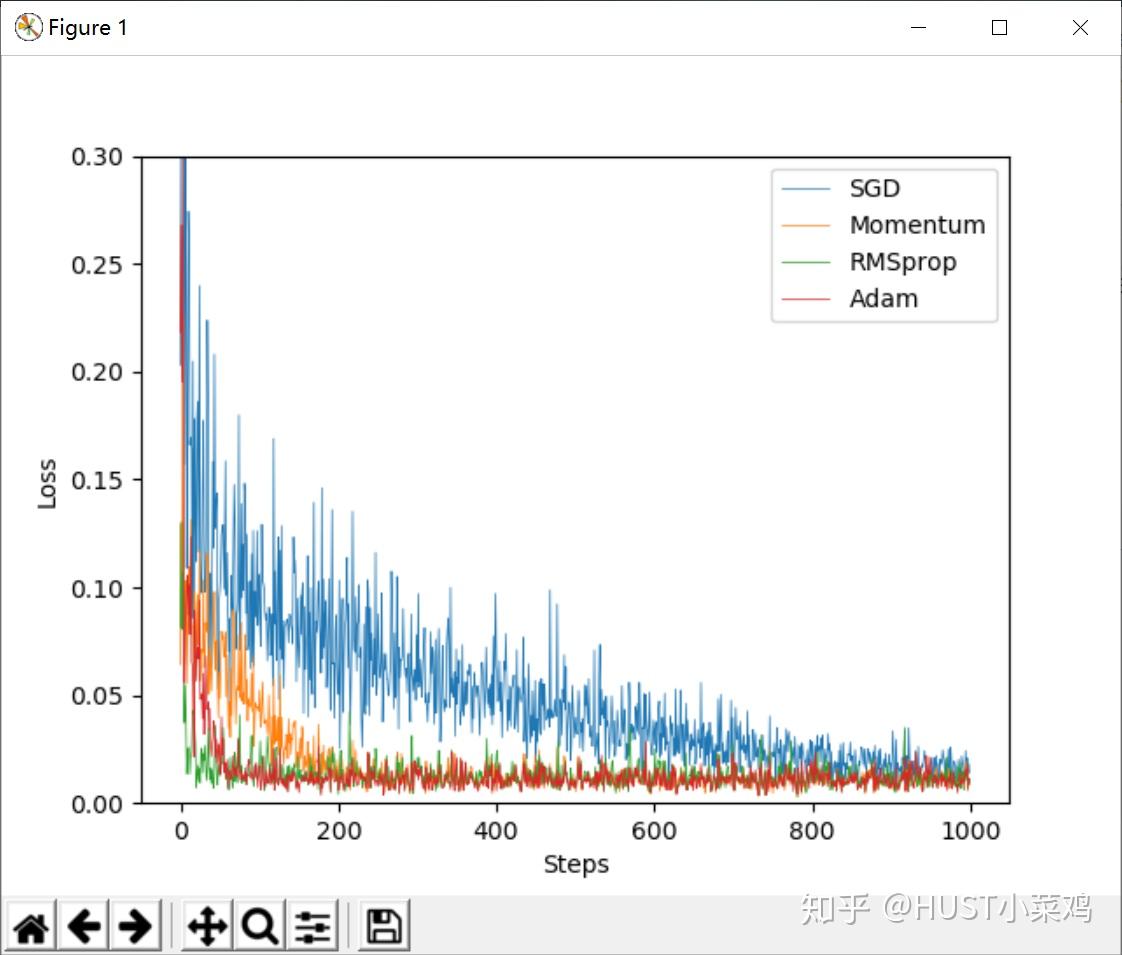
由结果可以看出不同的优化算法对于整个训练的收敛是有着不同的影响的,具有着不同的意义,(有的朋友说Adam算法容易爆显存,在训练的过程中要减小批处理数量,实践不多具体也不是很了解),不同的优化算法在不同的场合有着不同的功能和效果。
import torch
import torch.utils.data as Data
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.autograd import Variable
LR=0.01
BATCH_SIZE=20
EPOCH=20
x=torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y=x.pow(2)+0.1*torch.normal(torch.zeros(x.size()))
# plot data
# plt.scatter(x,y)
# plt.show()
torch_dataset=Data.TensorDataset(x,y)
loader=Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True)
class Net(nn.Module):
def __init__(self,n_input,n_hidden,n_output):
super(Net,self).__init__()
self.hidden1=nn.Linear(n_input,n_hidden)
self.hidden2=nn.Linear(n_hidden,n_hidden)
self.predict=nn.Linear(n_hidden,n_output)
def forward(self,input):
out=self.hidden1(input)
out=F.relu(out)
out=self.hidden2(out)
out=F.relu(out)
out=self.predict(out)
return out
net_SGD=Net(1,20,1)
net_Momentum=Net(1,20,1)
net_RMSprop=Net(1,20,1)
net_Adam=Net(1,20,1)
nets=[net_SGD,net_Momentum,net_RMSprop,net_Adam]
optimizer_SGD=torch.optim.SGD(net_SGD.parameters(),lr=LR)
optimizer_Momentum=torch.optim.SGD(net_Momentum.parameters(),lr=LR, momentum=0.8)
optimizer_RMSprop=torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR, alpha=0.9)
optimizer_Adam=torch.optim.Adam(net_Adam.parameters(),lr=LR, betas=(0.9,0.99))
optimzers=[optimizer_SGD,optimizer_Momentum,optimizer_RMSprop,optimizer_Adam]
loss_func=torch.nn.MSELoss()
losses_his=[[],[],[],[]]
for epoch in range(EPOCH):
print(epoch)
for step ,(batch_x,batch_y) in enumerate(loader):
# b_x=Variable(batch_x)
# b_y=Variable(batch_y)
b_x=batch_x
b_y=batch_y
for net,optimizer,loss_his in zip(nets,optimzers,losses_his):
net_output=net(b_x)
loss=loss_func(net_output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_his.append(loss.item())
labels=['SGD','Momentum','RMSprop','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i],lw=0.5)
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim(0,0.3)
plt.show()
学识浅薄,如有错误还请指正
手机:13988889999 公司地址:海南省海口市玉沙路58号 电 话:020-66889888 传 真:020-66889777 企业邮箱:admin@eyoucms.com |
|
020-66889888  |
 天游APP下载
天游APP下载 在线留言
在线留言 客服电话
客服电话
